Develop a Function to Read a Document in the Mongodb
Using Mongo Databases in Python
An introduction to MongoDB with PyMongo
![]()

MongoDB is a document based database with a dynamic information schema. The JavaScript Object Notation (JSON) that it supports is a natural fit for working with objects in modern programming languages like JavaScript, Python and others. This provides an alternative to more traditional Relational Database Management Systems (RDBMS) such as SQL. MongoDB is an example of a NoSQL databases. These databases often utilise collections of documents instead of the tables used in RDBMS. These databases support dynamic database schemas making them responsive to changes in the structure of data.
This brusk p rimer gives some examples of using MongoDB with Python using the pymongo library. This concludes by introducing mongoengine for working with Mongo databases in modern software projects every bit well as how to convert them into dataframe objects for further analysis. Information technology is assumed that readers are comfy downloading and setting up MongoDB and have some basic feel of using Python.
Structure
The structure of a document database differs from that of a relational database that stores data in rows (records) and columns (fields).
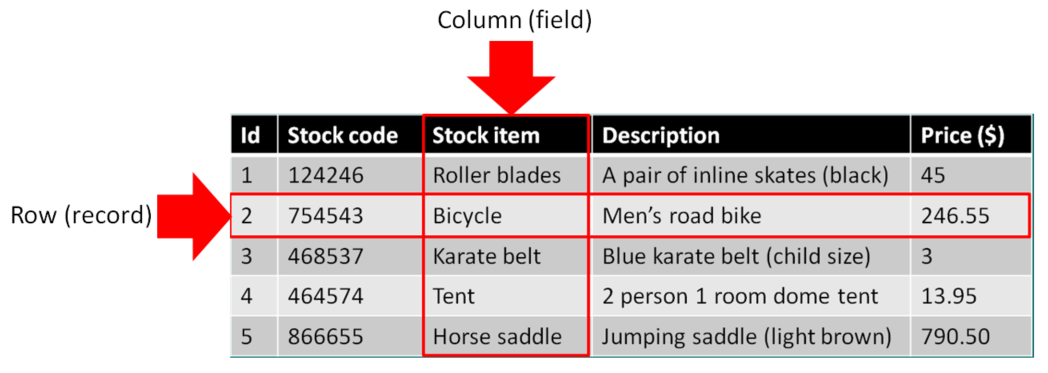
In this structure each cavalcade should just contain data of the aforementioned blazon. For example, we would simply look to see stock item data in the stock detail column. Any new information would crave making a new column or a new tabular array and so defining a human relationship betwixt the tables using a unique identifier (a primary fundamental) referred to as a foreign fundamental in subsequent tables. Changing the structure of this data, peculiarly when it already contains data tin can be more complex and may crave the use of migration tools.
In contrast to this MongoDB stores data as collections of documents using fundamental/value pairs:

Unlike relational databases where we would have to create a new column in a table to store information, data can be embedded. This means we just demand store what's relevant rather than creating redundancy.
Getting started
Pymongo is a Python driver for MongoDB allowing you to interact with Mongo databases using Python. You get-go demand to have installed MongoDB on your system. If y'all oasis't already done and so, you tin read how exercise that here: https://docs.mongodb.com/transmission/installation/
To apply pymongo, you first need to install the library, for example with pip in the Python prompt:
pip install pymongo Adjacent, we need to import the pymongo library into a Python file or Jupyter notebook.
import pymongo And then connect to a Mongo client. This connects on the default host and port.
client = pymongo.MongoClient("mongodb://localhost:27017/") We tin can then create a database to store some data. In this example it'southward going to store some details of patients for a wellness arrangement.
db = client["med_data"] Next, nosotros can add a collection to that database. Each database can comprise multiple collections. This collection volition be called patient_data and we volition reference the collection in Python using the variable my_collection.
my_collection = db["patient_data"] Inserting information
We can then add together some data (a document) to the collection. Let'southward say we wanted to store some bones details most a patient. This could include their proper noun, age, biological sexual practice and center rate. Nosotros will likewise store their blood pressure which is typically displayed with two numbers representing the systolic and diastolic force per unit area and is typically measured in millimetres of mercury (mmHg), for instance 156/82. In MongoDB, fields (data items) are encapsulated inside braces ({}) using JavaScript object notation. Each field consists of a key/value pair. The field name (fundamental) is enclosed in quotation marks followed by a colon and so the related value. Textual (text information) values are as well encapsulated in quotation marks, numbers (numeric data) are not. Values tin can also contain other objects and arrays. Arrays can store lists of data and other primal value pairs and are denoted with the foursquare brackets ([]). Here nosotros tin can shop the keys and values for the systolic (sys) and diastolic (dia) claret pressure along with the data values.
patient_record = {
"Proper name": "Maureen Skinner",
"Age": 87,
"Sex": "F",
"Blood pressure level": [{"sys": 156}, {"dia": 82}],
"Heart rate": 82
} Multiple documents can exist added by simply adding a comma subsequently the closing brace and adding additional objects. The dissimilar objects can as well contain completely different data fields every bit required.
One time nosotros have created a document(s), we can add it to the collection. To add a single document we first specify the collection we desire to add in to followed by a dot then nosotros can utilize the insert_one function (for many we use the insert_many) passing in the document object variable:
my_collection.insert_one(patient_record) To view the contents of the collection we can loop over each item of the collection and impress information technology.
for item in my_collection.discover():
print(particular) This volition output the data like and then:

Viewing the data this mode makes it quite difficult to read especially if you have a lot of fields and documents to output. Fortunately Python has a pretty print library for just such a purpose. If nosotros modify the code to import the library and use the function (note the double 'p' in impress):
from pprint import pprint for item in my_collection.find():
pprint(item)
You tin see that it outputs the information in a much easier to read format:
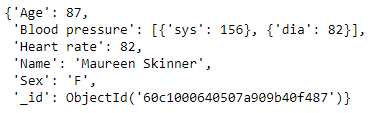
Note that MongoDB automatically adds an ObjectId to uniquely identify each certificate. This is a 12-byte hexadecimal cord consisting of a timestamp, randomly generated value and incrementing counter. These id's are displayed when information is output. You can also override this by providing your own values for the "_id" field if required.
We can add multiple records at a time using the insert_many function:
patient_records = [
{
"Proper noun": "Adam Blythe",
"Age": 55,
"Sex": "1000",
"Blood pressure": [{"sys": 132}, {"dia": 73}],
"Centre charge per unit": 73
},
{
"Name": "Darren Sanders",
"Historic period": 34,
"Sex activity": "M",
"Claret force per unit area": [{"sys": 120}, {"dia": 70}],
"Heart rate": 67
},
{
"Name": "Sally-Ann Joyce",
"Age": 19,
"Sex": "F",
"Blood force per unit area": [{"sys": 121}, {"dia": 72}],
"Centre rate": 67
}
] my_collection.insert_many(patient_records)
Updating data
We may also want to update data that we take previously added to a drove. Once more we tin update a single or multiple records. Allow's say we accidentally added the same heart rate for Darren Sanders and Emerge-Ann Joyce. Darren's was supposed to be 88. Here we can use the update_one part passing in the field we want to update searching for the key/value pair "name" and "Darren Sanders" then we use the $ready choice (preceded by a dollar sign) specifying the key (centre rate) and the new value (88). This volition overwrite the initial value with the new one.
my_collection.update_one({"Proper name": "Darren Sanders"}, {"$set":{"Centre rate": 88}}) As you have seen, nosotros can nest multiple layers of objects and arrays in ane another thus embedding information. Another option is to separate out data in a divide collection and link to it. We will await at both embedding and linking and questions to aid you determine which is best to use.
Embedding or linking data
We can nest data by embedding it. Consider that we want to store some medical test results for a patient. This could include some blood test results and an ECG/EKG prototype for some investigations for a heart attack and some claret tests, including:
- Creatine Kinase (CK)
- Troponin I (TROP)
- Aspartate aminotransferase (AST)
We can start by creating a field called "test results" which contains an assortment.
patient_record = {
"Hospital number": "3432543",
"Name": "Karen Baker",
"Age": 45,
"Sexual activity": "F",
"Blood pressure": [{"sys": 126}, {"dia": 72}],
"Heart charge per unit": 78,
"Test results" : []
} Inside this array we tin store objects for the ECG (a path to the epitome file) and another array to shop the biochemical results.
patient_record = {
"Hospital number": "3432543",
"Name": "Karen Baker",
"Age": 45,
"Sexual activity": "F",
"Claret pressure": [{"sys": 126}, {"dia": 72}],
"Heart charge per unit": 78,
"Test results" : [
{
"ECG": "\scans\ECGs\ecg00023.png"
},
{
"BIOCHEM": []
}
]
} Finally, we tin add the claret results as key/value pairs:
patient_record = {
"Hospital number": "3432543",
"Name": "Karen Baker",
"Age": 45,
"Sexual activity": "F",
"Blood force per unit area": [{"sys": 126}, {"dia": 72}],
"Heart rate": 78,
"Examination results" : [
{
"ECG": "\scans\ECGs\ecg00023.png"
},
{
"BIOCHEM": [{"AST": 37}, {"CK": 180}, {"TROPT": 0.03}]
}
]
} We can write these on the same line like nosotros did with the blood pressure or on separate lines to aid with readability.
An alternative to embedding data in this mode is to instead link to it. Linking data is likewise chosen referencing. This involves storing data in a different collection and referencing information technology past id. Deciding whether or not to link or embed data is dependent on certain considerations, such every bit:
- How ofttimes you need to access the embedded data?
- Is the data queried using the embedded information?
- Is the embedded data subject field to frequent change?
- How ofttimes practice y'all demand to access the embedded data without the other information it's embedded in?
Depending on the answer to these questions, you may want to link to the data instead. Consider the following example. You may want to store some information well-nigh what drugs have been prescribed for a given patient. You could embed this information, but what if you too wanted to store more generic information about the medication also. Here yous could have a separate drove with such data that you could link to.
medication_data = [
{
"_id": ObjectId('60a3e4e5f463204490f70900'),
"Drug proper noun": "Omeprazole",
"Type": "Proton pump inhibitor",
"Oral dose": "20mg one time daily",
"IV dose": "40mg",
"Net price (GBP)": iv.29
},
{
"_id": ObjectId('60a3e4e5f463204490f70901'),
"Drug proper name": "Amitriptyline",
"Type": "Tricyclic antidepressant",
"Oral dose": "thirty–75mg daily",
"Four dose": "N/A",
"Net toll (GBP)": ane.32
}
] We tin can apply the id'south and the DBRef function to reference this information in another collection. For example:
from bson.dbref import DBRef patient_records = [
{
"Hospital number": "9956734",
"Name": "Adam Blythe",
"Age": 55,
"Sex activity": "Yard",
"Prescribed medications": [
DBRef("medication_data", "60a3e4e5f463204490f70900"),
DBRef("medication_data", "60a3e4e5f463204490f70901")
]
},
{
"Hospital number": "4543673",
"Name": "Darren Sanders",
"Age": 34,
"Sex": "Yard",
"Prescribed medications": [
DBRef("diagnosis_data", "60a3e4e5f463204490f70901")
]
}
]
Querying data
There are several methods for querying data. All of the methods use the find() function. A query tin exist provided followed past the field or fields you wish to return in the course:
collection.find({ <query> }, { <field(s)> }) To find a single entry, for example the patient with the name "Darren Sanders" nosotros could utilize the observe office and print the first item in the list:
pprint(my_collection.find({"Name": "Darren Sanders"})[0] Nosotros could as well use a loop to output the results. We tin also shop the query in a separate variable that we pass into the find function start. This is useful when the query might be complex as it helps with the readability of the code:
query = {"Name": "Darren Sanders"} medico = my_collection.find(query)
for i in doc:
pprint(i)
Finally, if we only want a unmarried result we tin can utilize the find_one() function:
my_collection.find_one({"Name": "Darren Sanders"}) A mutual thing to do with databases is to query a subset of data depending on certain criteria. Nosotros tin can utilize comparison operators to retrieve subsets of data. For example nosotros could use the greater than operator ($gt) to search for all patient names with a heart rate > 70 beats per infinitesimal.
for heart_rate in my_collection.find({"Centre rate": {"$gt": seventy}}, {"Proper noun"}):
pprint(heart_rate) In that location are many such comparison operators bachelor, including:
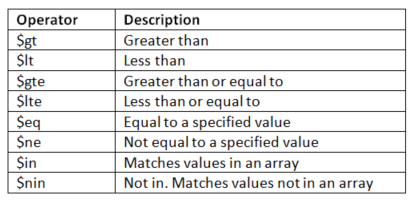
This functionality tin be further enhanced by using logical operators. For example, we could search for patients with a center rate < lxx beats per minute, and who are aged above twenty years.
result = my_collection.find({
"$and" : [
{
"Middle rate": {"$lte": 70}
},
{
"Age": {"$gt": 20}
}
]
}) for pt in result:
pprint(pt)
Logical operators include:

You might be wondering how nosotros find data that'due south contained in arrays. This can be washed past using a menstruation (dot). For case yous may recall that we stored the patients' systolic and diastolic blood pressure similar so:
"Claret pressure level": [{"sys": 126}, {"dia": 72}] Nosotros could query patients with a systolic (sys) claret force per unit area less than 140 mmHG (mm of mercury) similar so:
for normal in my_collection.notice({"Blood pressure.sys": {"$lt": 140}}):
pprint(normal) Note that we reference the key "blood pressure" add a menstruum (dot) and and so the key inside the array, for example sys for systolic.
Working with existing data
1 of the great things virtually MongoDB is that it is really straight frontwards to load JSON files and add them to collections. For instance if we had some JSON information stored in a JSON file, we could use the json library to read in this data and add it to a MongoDB collection:
import json with open('data_file.json') equally f:
file_data = json.load(f)my_collection.insert_many(file_data)
You wouldn't want to output the unabridged contents of a database with hundreds of thousands of documents. To view the file and come across the structure of the information, you lot may instead output the first n documents instead. For example the start 10 documents. This tin exist accomplished using the limit() role.
for item in my_collection.find().limit(x):
pprint(item) To check the number of documents in a drove we can use the count_documents function like so:
my_collection.count_documents({}) Once more we could add a query here to count all the documents that meet some criteria of interest.
Assemblage
Frequently when working with data we don't but desire to extract subsets of data using queries, we instead want to produce new data from the existing data. This often involves carrying out various calculations similar finding the average or sum of some value. For example the average wage of employees.
Let'due south wait at a brief example using a sample dataset containing details of restaurant data (the data tin be found here: https://docs.atlas.mongodb.com/sample-information/available-sample-datasets/).
An case certificate can exist seen below:
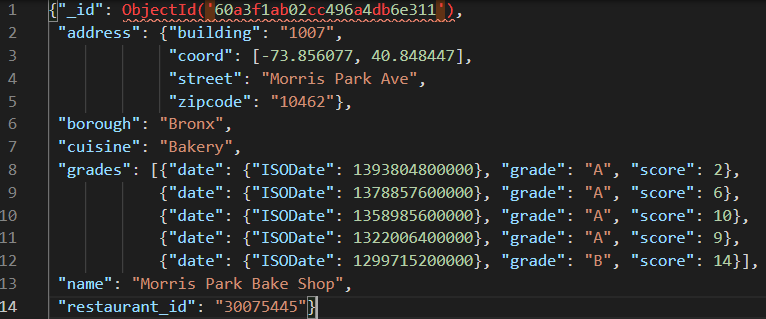
You lot can see details of the restaurant address, which borough it is in, the blazon of cuisine, name, id and details of grades awarded with associated scores. Permit's say we wanted to compute the average scores of the restaurants. To attain this nosotros tin can use the aggregate office.
outcome = my_collection.amass(
[
{"$unwind": "$grades"},
{"$friction match": {}},
{"$group": {"_id": "$proper name", "Avg form": {"$avg": "$grades.score"}}}
]
) We pass an array to the aggregate role. The $unwind parameter is used to deconstruct the grades array in order to output a certificate for each chemical element. Next we use the $match parameter including everything (by using open and closing braces). We could filter further hither past providing additional criteria. Next we apply the $group parameter to group the information that nosotros want to use the computation to. Finally we create new key called "Avg grade" and apply the $avg (average) parameter to the grades scores referencing grades followed by a dot and the score primal.
Producing the following output (shortened for brevity):
{'Avg grade': fifteen.ii, '_id': 'Red Star Restaurant'}
{'Avg form': 13.0, '_id': 'Weather Upward'}
{'Avg grade': 9.4, '_id': 'La Nueva Playitas'}
{'Avg class': thirteen.0, '_id': "Marcella'S Pizzeria & Catering"}
{'Avg form': 9.0, '_id': 'Hot Wok'}
{'Avg grade': 9.333333333333334, '_id': '99 Favor Taste'}
{'Avg form': xviii.0, '_id': 'Flavors Corner'}
{'Avg grade': 10.666666666666666, '_id': 'Corona Eatery'}
{'Avg course': 9.0, '_id': 'Mila Cafe'}
{'Avg course': 8.0, '_id': 'Circle Line Manhattan'}
{'Avg class': 15.vi, '_id': "The Former Fourth dimension Vincent'Southward"}
{'Avg grade': 10.833333333333334, '_id': 'Riko'}
{'Avg course': x.0, '_id': 'Fresh Tortillas'}
{'Avg grade': 10.333333333333334, '_id': 'Le Village'}
{'Avg grade': 13.ii, '_id': 'Ruay Thai Restaurant'}
{'Avg course': 12.0, '_id': 'Lechonera Don Pancholo'}
{'Avg grade': xi.0, '_id': 'Pepe Rosso Social'}
. . . There are many other parameters that can exist used for common computations such equally $sum, $min, $max etc.
Nosotros can as well add additional functionality as required. For example we might want to sort the returned in ascending or descending society. Nosotros could merely add another line with the sort parameter specifying which field to sort by. 1 (ascending) or -1 (descending).
result = my_collection.amass(
[
{"$unwind": "$grades"},
{"$match": {}},
{"$group": {"_id": "$name", "Avg grade": {"$avg": "$grades.score"}}},
{"$sort": {"Avg class": -1}}
]
) Another option to sort without using the aggregate function is to apply the sort role directly passing in the field name, for example sorting by name:
for item in my_collection.observe().sort("name").limit(x):
pprint(item) We can choose ascending/descending by calculation a ane or -ane later the field to sort:
for detail in my_collection.detect().sort("name", -1).limit(10):
pprint(item) Using MongoDB in software projects and for information science
Ane of the primary advantages of MongoDB using the JSON format is the interoperability that this provides with programming languages that use a similar format. This makes working with information in an application and storing/retrieving it from a database nigh seamless.
A better style of integrating a database into code is to apply a method such as Object Relational Mapping (ORM), or in the case of MongoDB an Object Document Mapper (ODM). This works by translating Python (or some other languages) code into MongoDB statements to retrieve information. This data is then passed back into Python objects. This has the advantage of ensuring that you merely need to employ one language (e.one thousand. Python) to admission and use the database.

A adept library for doing this is mongoengine. Here we import the library and connect to a Mongo client which we volition phone call odm_patients.
from mongoengine import *
connect('odm_patients') The following case shows how nosotros can create a Python class to model some information, create a few instances of that grade and write this to a database. Following the previous example nosotros will create a class to store data about patients.
class Patient(Document):
patient_id = StringField(required=Truthful)
proper name = StringField()
age = IntField()
sex = StringField(max_length=one)
heart_rate = IntField() We can use a Python class to create an object to manipulate the database. Here we create the data items by specifying what sort of field they are. For example textual/string information can be created using a StringField() function and integers with IntField(). Additional parameters can also exist added such as the corporeality of characters in a cord and if a field cannot be null/empty.
We can now create instances of this class in the standard way in Python. Here nosotros can create a couple of patients called Maxine and Hamza. Note that we add the save() function to the stop of the line to write this data to the database.
maxine_patient = Patient(patient_id = "342453", name = "Maxine Smith", historic period = 47, sex = "F", heart_rate = 67).salve() hamza_patient = Patient(patient_id = "543243", name = "Hamza Khan", age = 22, sex = "M", heart_rate = 73).save()
Nosotros tin can output these objects using a loop. To admission specific fields nosotros can use the iterator, a dot and and then the field we wish to output. For example the patients name, id and historic period.
for patient in Patient.objects:
impress(patient.proper name, patient.patient_id, patient.age) Which produces the following output:
Maxine Smith 342453 47
Hamza Khan 543243 22 Apart from integrating Mongo databases into software projects, nosotros tin too utilize this for research and data science/assay tasks likewise. There is an like shooting fish in a barrel way to convert data from a Mongo database into tabular form as a Panda'southward dataframe object. Firstly we import the pandas library.
import pandas every bit pd Next we select the required information using a standard query, for example we will remember all the names for bakeries in the Bronx. Adjacent we convert the results into a list data construction.
extracted_data = my_collection.find({},{"civic": "Bronx", "cuisine": "Bakery", "proper noun": 1})
bronx_bakeries = list(extracted_data) Finally we create a data frame using the from_dict function to convert the dictionaries into a tabular data frame:
pd.DataFrame.from_dict(bronx_bakeries) This produces the post-obit output:

In summary, MongoDB is a powerful and scalable database that is very useful when the data schema is prone to frequent change. This lends itself to integration with mod software systems easily and tin besides be used as office of a data analysis pipeline when analysing data in JSON format, such equally some mobile app information or Twitter data. MongoDB is i of the most popular NoSQL databases and an awareness of what information technology is and how it works is a must for software engineers and data scientists.
darbyfecloseraves76.blogspot.com
Source: https://towardsdatascience.com/using-mongo-databases-in-python-e93bc3b6ff5f
0 Response to "Develop a Function to Read a Document in the Mongodb"
Post a Comment